


Mobotix presents the case for use of high-resolution digital surveillance systems.
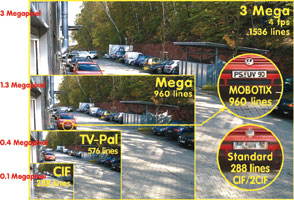
Even basic digital cameras provide more definition than the images from CCTV camera systems that are commonly used to identify terrorists. A simple comparison between digital and older technology clearly highlights the difference in image detail: the simplest of digital cameras stores images of around 3 million pixels (3 megapixels); in comparison, the classic video technology is restricted to 1/30 the pixels (101 000 pixels or 0,1 megapixels). Even the most inexperienced amateur photographer would not buy such a low-resolution camera these days. Despite these facts, this kind of security camera system is still being specified and deployed in a large number of public safety applications.
The poor quality of the images used in these public safety applications is not, as one would imagine, a result of the currently available technology, but rather the systems specified as the systems of choice. These, in turn, are based on television technology more than 50 years old, using video cameras that deliver live images with a maximum of 0,4 megapixels. Due to technical and cost constraints of these systems, the images are further reduced by a factor of 4:1 to just 0,1 megapixels, making facial recognition almost impossible.
Issues: 0,4 megapixels
So why do we not store the original image in 0,4 mega pixels? There are video systems that can store images at 0,4 megapixels, however, these are expensive and do not give the user sufficiently more detail. TV technology standard – the video stream is broadcast in half frames, and as the name suggests these have only half the detail. The electronic fitting together, or interlacing, of these half frames when viewing or recording moving objects, which is the most important aspect of security surveillance, causes combing distortion (blurred edges) in the image.
The image delivered by a video camera has 576 lines made up of two half frames, each with 288 lines, which are, exposed consecutively one after the other and then transmitted. Because of the technical and financial considerations mentioned earlier, most of the systems in use today are digitising and storing on a half frame basis. In context with the width to height ratio, 352 horizontal pixels are digitised for each of the 288 lines resulting in a so-called CIF image with 352 x 288 = 101 000 pixels, which is equivalent to 0,1 megapixels.
The 2CIF image format also uses only 288 lines but combines them with double the amount of pixels per line, giving us around 0,2 megapixels. Despite the increase in pixels per line, a considerable amount of important information is still missing from the image because every second line within each image is simply ignored, leaving us with what is accurately described as a half frame or half image.
Made up of two interlaced consecutive half images, a 4CIF format has indeed 704 x 576 = 0,4 megapixels but every second line is staggered or deferred because the half frames are exposed at different times. Because of this so-called combing effect, 4CIF recording is hardly ever used in actual systems. For example, at the World Cup stadiums only CIF, or in some cases 2CIF, half frames were recorded.
Snapshots unreliable in facial recognition
An additional problem with existing video technology lies in the low refresh rate of recorded images during playback. Again, because of technical and cost factors, 95% of existing systems cannot achieve more than 1-3 frames per second. With such a low refresh rate of snapshots, it becomes very difficult to find an image with enough detail for facial recognition.
This low playback rate is the result of one single computer having to digitise and store video feed from multiple cameras. The computing power for full video is generally only sufficient for two cameras; therefore, when recording more cameras the frame rate has to be drastically reduced.
Because of this limited processing power, MPEG4 also cannot be implemented for the recording of high-resolution video. The processing power is just not available for multiple cameras.
Why do the traditional surveillance camera manufacturers not simply use high-resolution sensors in their video cameras? The clear, but far from comforting answer is that the standard the systems are based on for the transmission and recording of images is 50 years old and it is technically impossible for the video cable to process such high-resolution images. Understandably, the video surveillance industry is reluctant to change; however, to protect the public, change is inevitable.
The digital difference: IP cameras
New digital technologies also present opportunities for innovative manufacturers to offer new solutions. In the last few years, there has been an emphasis on developing megapixel technology and transmitting video streams via modern computer networks, LAN, WAN, WLAN or over the Internet. In order to achieve this, a high-performance processor with extensive software package for processing, compressing, recording and storage of the image sequences was developed and integrated into the video camera itself.
One of the great advantages of modern network camera technology is the ability to manage all configurations and to access live and stored images simultaneously while the camera is recording, remotely over the network, anytime, from anywhere in the world. These camera installations will be linked on the existing company network or even the Internet via a secured connection (VPN) and firewall.
In this way, any incident or suspicious behaviour in a train station, airport or any other public place can be immediately investigated by retrieving the images to the control centre via the network without the necessity of having someone on site or having to stop the recording and live viewing. New or improved software for further functionality can simply be loaded into the camera through the network.
The use of worldwide IT standards makes it possible to integrate inexpensive system components: whether over copper, glass or wireless via WLAN. A power outlet is not necessary as cameras do not require heating to prevent misting and as a result can be supplied with power via the network cable all year round.
A direct comparison
A comparison of a CIF image with 288 lines and a camera image with 960 lines dramatically highlights the difference in quality and detail. Megapixel imaging shows 12 times more detailed resolution, so that a face taking up only 1/40th of the image width is still clearly recognisable. With the appropriate post editing, the image quality can be further improved. In comparison, the image extracted from the CIF image is unrecognisable and therefore unusable.
Many IP cameras or network cameras are still using the old analogue technology internally and merely transmit a digitised image via a computer network. Although it is hard to believe, most IP camera systems are only storing CIF half frames!
Switching from MPEG4 TO MXPEG
The video standard MPEG4 was developed for compressing a single video stream (e.g. movie) and not for the compression, management and viewing of multiple high-resolution cameras. MPEG4 transmits moving objects at lower resolution and quality because the human eye does not take in all the detail of a moving object; therefore, it makes no difference when watching a movie. For this very reason, MPEG4 is not suitable for security systems because in a security situation, it is these moving objects that are of great importance and must be therefore highly detailed.
To handle the needs of security video, the video standard MxPEG, requiring around only 2 Mbps for a high-resolution video stream and exhibiting a shorter reaction time than MPEG4 is ideal. The MxPEG standard is currently being implemented and supported by manufacturers and developers worldwide.
For more information contact IAC, +27 (0)12 657 3600, , www.iaconline.co.za
| Tel: | +27 12 657 3600 |
| Email: | [email protected] |
| www: | www.iacontrol.co.za |
| Articles: | More information and articles about Industrial Automation & Control (IAC) |


© Technews Publishing (Pty) Ltd. | All Rights Reserved.
 printer friendly version
printer friendly version